Разработана новая система дикторонезависимого распознавания слитной речи для русского языка с помощью технологий машинного обучения и глубокого обучения искусственных нейронных сетей. Получены актуальные результаты исследования в области компьютерной лингвистики, морфологического, синтаксического и семантического анализа текстов на естественном языке. Создание подобных программ, позволяющих компьютеру, работая с естественным языком, решать задачи, доступные пока только для человека, представляет несомненный интерес с точки зрения искусственного интеллекта.
Разработан программный модуль для автоматической адаптации текстов, позволяющий сокращать текст путем удаления фрагментов, которые могут быть опущены без существенных потерь для общего содержания текста и замены отдельных слов и словосочетаний их более общими синонимами. Модуль может использоваться при автоматическом анализе и обработке текста для задач аннотирования, поисковой оптимизации и автоматического реферирования текстов.
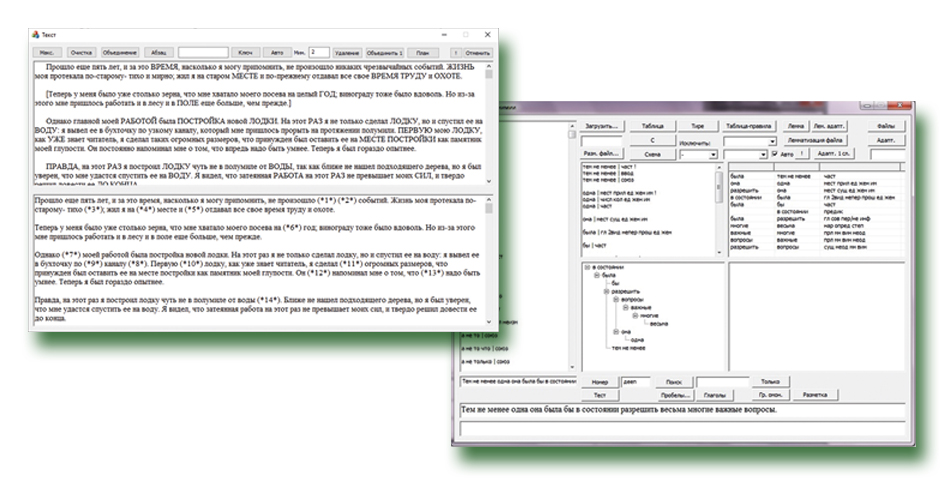
В настоящее время ведутся работы в области автоматического снятия неоднозначности слов при анализе русскоязычного текста на морфологическом уровне. К основным задачам морфологического анализа относится определение морфологических характеристик. Например, для словоформы «шоколада» распознаются характеристики: существительное, родительного падежа, единственного числа, мужского рода. Актуальность определяется тем, что омонимия значительно осложняет автоматическую обработку текста. Словоформы, имеющие одинаковое написание, но разное прочтение. Для русского языка эта проблема особенно актуальна. Поэтому процедура снятия омонимии является важным и необходимым этапом для качественной компьютерной обработки и анализа текстов и, в конечном итоге, понимания и извлечения знаний из них. Результаты разрешения омонимии могут использоваться для повышения точности методов классификации и кластеризации текстов, улучшения качества машинного перевода, информационного поиска, автоматического реферирования текста и других приложений.